Welcome back to my Splunk series. Let’s continue our journey with Splunk.
Splunk 101
What data can Splunk ingest? First, let us take a view of Splunk at 1000 feet.
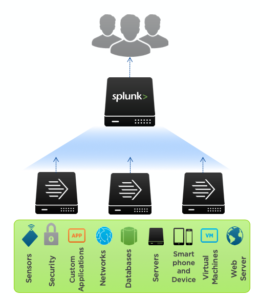
One thing that Splunk strives for is can ingest any data. Splunk software collects and indexes data from virtually any source, whether structured in databases, unstructured in a data lake, or previously unknown (dark). Machine data is dark; this high-volume, high-velocity data is highly variable and incredibly diverse — and simply overwhelming for traditional system management, SIEM, CEP/ECA, and log management.
The green box in the image gives you an idea of the devices and infrastructure you can gather data.
Infrastructure
Why do I need infrastructure? It would be best if you made this infrastructure decision upfront. For example, do you want your data to be in a single instance or distributed? If you choose a single instance, you cannot change it. You have to build a new infrastructure for distribution.
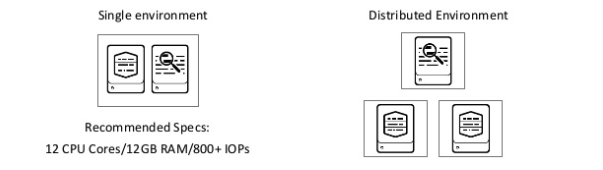
In the image above, you can see some recommended Specs; we will talk about that later in this blog.
Architecture
Architecture is a big subject when it comes to Splunk. Each piece has a responsibility, and not all parts are required. Here is a high-level Architecture of Splunk.
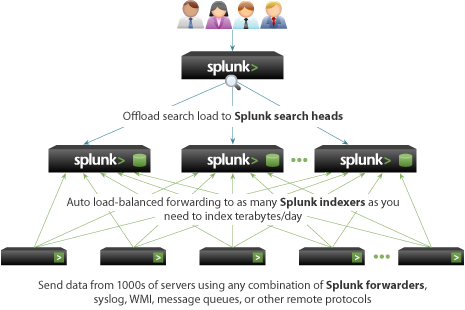
Required fundamental components
Indexer
The indexer process the incoming data in real-time. It also stores and indexes the data on disk. An indexer has two types:
- standalone
- peer node in a cluster
Search Head
End-users interact with Splunk through search head(s). It allows users to do searches, Analysis & Visualization. A search head has five types:
-
Independent search head
-
A search head node of an indexer cluster
-
A member of a search head cluster
-
A search head node of an indexer cluster and a member of a search head cluster
-
A member of a search head pool
Advanced components
Forwarder
Forwarder collects the data from remote machines and then forwards data to the Index in real time. A search head has three types:
-
Universal forwarders
- Universal Forwarders provide reliable, secure data collection from remote sources and forward that data into Splunk software for indexing and consolidation. They can scale to tens of thousands of remote systems, collecting terabytes of data.
-
Heavy forwarders
- A heavy forwarder has a smaller footprint than a Splunk Enterprise indexer but retains most of the capabilities of an indexer. An exception is that it cannot perform distributed searches. In addition, you can disable some services, such as Splunk Web, to further reduce its footprint size.
- Unlike other forwarder types, a heavy forwarder parses data before forwarding it and can route data based on criteria such as source or type of event. It can also index data locally while delivering the data to another indexer.
-
Light forwarders
- A light forwarder has a smaller footprint with much more limited functionality. For example, it forwards only unparsed data. The universal forwarder, which provides very similar functionality, supersedes it. The light forwarder has been deprecated but is available mainly to meet legacy needs.
Deployment
The deployment server helps to deploy the configuration. For example, update the universal forwarder configuration file. In addition, we can use a deployment server to share between the component we can use the deployment server.
Master
The controller node manages the cluster. It coordinates the replicating activities of the peer nodes and tells the search head where to find data. It also helps control the configuration of peer nodes and orchestrates remedial actions if a peer goes offline.
Unlike the peer nodes, the master does not index external data. Therefore, a cluster has exactly one controller node.
Deployer
The deployer is a Splunk Enterprise instance that distributes apps and other configurations to the cluster members. Therefore, it stands outside the cluster and cannot run on the same example as a cluster member. It can, however, under some circumstances, reside on the same instance as other Splunk Enterprise components, such as a deployment server or an indexer cluster controller node.
License Master
The license master controls one or more license slaves. From the license master, you can define stacks, and pools, add licensing capacity and manage license slaves.
Monitoring Console
The Monitoring Console is a search-based monitoring tool that lets you view detailed information about the topology and performance of your Splunk Enterprise deployment. The Monitoring Console provides pre-built dashboards that give you visibility into many areas of your deployment, including search and indexing performance, resource usage, license usage, and more. In addition, you can use the Monitoring Console to track the status of all deployment topologies, from single-instance (standalone) deployments to complex multi-site indexer clusters.
Scalability
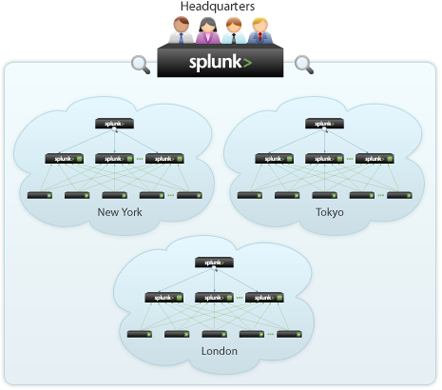
To support larger environments where data originates on many machines in many locations and where many users across the globe need to search the data, you can scale your deployment by distributing Splunk instances across multiple machines and locations.
Splunk performs three critical functions as it processes data:
-
It ingests data
-
It parses and indexes the data
-
It runs searches on the indexed data
To scale Splunk, you can split this functionality across multiple specialized instances of Splunk. These instances can range from just a small amount to many thousands, depending on the quantity of data you are dealing with and other variables in your environment. Below is an image of a possible Splunk deployment across multiple regions.
Summary
You should have a 101 mentality of Splunk and its architecture. I will dive deeper into the information required to size the Splunk environment in the following Splunk blogs.